
Aujourd’hui je vais sortir un article des brouillons suite à 2 articles que j’ai pu lire ces 2 dernières semaines. Le premier qui est en fait l’écoute du podcast de Julien chez Laurent Bourrelly et le second un article de Julien expliquant ce qu’il lui est arrivé en balançant son réseau sur twitter. Donc avant toutes choses et pour que cela soit bien clair pour la suite de l’article, je tiens à préciser que je n’ai absolument rien contre Julien. C’est juste le déclencheur de la reprise d’activité sur ce blog 
L’anonymat, l’allié des réseaux de sites
Monter un réseau de sites et lui donner un minimum de power, cela peut parfois prendre du temps (tout dépend du niveau d’automatisation que vous avez mis en place en amont ET en aval). Le rendre intraçable est une des conditions qui doit être réfléchie avant la création de ce réseau et cela pour différentes raisons :
- Ne pas montrer à Google : « Hey man, t’as vu tous ces sites. Ce sont les miens !! »
- Ne pas montrer à vos concurrents : « Hey men, vous avez vu ces sites. Ce sont les miens !! »
- Eviter que quand votre famille tape votre nom de famille dans un moteur de recherche, elle tombe sur des résultats de whois avec des NDD qui sont parfois assez explicites (vous savez les fameux EMD).
Ainsi pour éviter de se faire tracer, le gestionnaire de réseau doit prendre plusieurs précautions :
- Ne pas mettre ses sites dans GWT (où alors avec des identités différentes, mais bon à éviter quand même)
- Faire attention avec les codes de tracking analytics (que ce soit avec Piwik, GA, …).
- Faire attention avec les codes d’affil et de ads
- Bloquer les bots indésirables via .htaccess
- Prendre des whois anonymes
- Ne pas mettre tous ses sites sur le même serveur. Varier au max les IP
- Varier au max les templates et CMS des sites de son réseau
- Faire attention à certains plugins de CMS (je pense notamment à mainWP, mais il y en a d’autres)
- Faire attention aux fichiers que vous incluez sur vos sites (js, css). C’est parfois un aspect qui est négligé et qui permet de remonter un réseau, comme nous pourrons le voir par la suite.
Comment réussir à identifier et obtenir un réseau
Il existe plusieurs façons pour identifier un réseau de sites. En fonction des précautions que le gestionnaire du réseau aura prises, certaines de ces solutions seront inefficaces.
Le Whois
Le whois d’un nom de domaine recense les informations sur les coordonnées de l’hébergeur, du propriétaire, du contact technique … . Sur linux la commande « whois » permet d’obtenir ces informations. Mais il existe une multitude de sites qui permettent d’obtenir ces informations, comme par exemple : http://whois.domaintools.com/
Pour obtenir la liste des sites appartenant à une personne donnée, un footprint comme celui-ci fera l’affaire :
"Nom" + "Adresse" + site:whois.domaintools.com
Les sites hébergés sur la même adresse IP
Comme nous l’évoquions précédemment, certains sites sont hébergés sur un serveur dédié avec la même adresse IP. Pour cela, je vous renvoi sur un POC que j’avais publié en 2011 : https://www.renardudezert.com/2011/02/14/lopportunite-souvent-negligee.html
Les fichiers « inclus »
C’est ce dernier point qui sera le plus souvent négligé lors de l’élaboration d’un réseau. Jusqu’il y a peu de temps, il n’existait pas de moteurs qui permettaient d’effectuer des recherches dans le code source des pages qu’ils avaient crawlées. Mais avec l’explosion et la « mode » du Big Data de ces dernières années, certains moteurs se révèlent très efficaces dans ce domaine. Je vais vous parler de nerdyData, qui lorsqu’il était sorti s’annonçait déjà prometteur (cf ce RT).
Pour en revenir au cas de Julien, il y a bien sur l’effet twitter qui est indéniable. Mais si la personne qui a balancé le réseau était un peu plus maline, elle aurait pu identifier le réseau d’une autre manière.
Voici comment je suis arrivé à retrouver des sites en quelques clics. La première « erreur » vient d’un script inclus (bha oui, c’est quand même le titre de cette section).
Il me permet de récupérer déjà pas mal de sites (230 pour être exact).
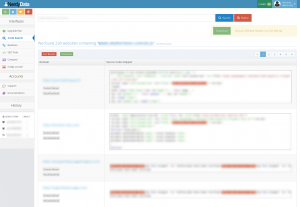
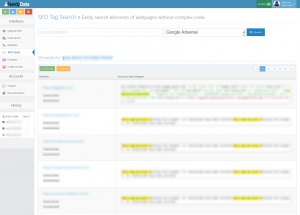
Pour aller encore plus loin, il suffit ensuite de scraper chaque site, de récupérer les status code pour vérifier ceux qui sont en ligne, de récupérer les id adsenses, de dédoublonner et de retourner sur nerdyData pour obtenir les résultats. Voici ce que j’obtiens par exemple pour un id (59 résultats via nerdyData, contre 50 via SpyOnWeb) :
Conclusion
Tout d’abord, je tiens à souligner que je ne veux pas faire la morale sur la bonne ou mauvaise gestion d’un réseau de sites. Ce n’est clairement pas le sujet de cet article. Je souhaitais juste donner plusieurs pistes aux personnes qui gèrent un où plusieurs réseaux de sites et qui souhaitent cloisonner au maximum. Il suffit parfois juste d’un petit oubli pour obtenir plusieurs sites d’un réseau. Keep it in mind 
P.S. : Pour ceux qui souhaitent savoir comment bloquer le bot de nerdyData, voici la marche a suivre : http://nerdybot.com/ (et préférez le .htaccess au robot.txt :))














